分析用雛形~Classification~(★)¶
いろんな機械学習のアルゴリズムを試したいときに、拡張可能なものを作った。AzureやAWSにもある。ドラッグアンドドロップのものもあるはず。
システム化を念頭において、デザインパターンをpythonで実装してみた。
定期的にアップデート予定。(azure モジュール呼び出してみる)
各セクションへのリンク:
パイプライン : frame_pipeline
モデル : frame_model
実行 : frame_main
Pipeline¶
Pipelineを作成するにあたりFactory パターンを利用した。Factory Methodについては下記のようなクラス図がかける。抽象クラスでも作れると思う。
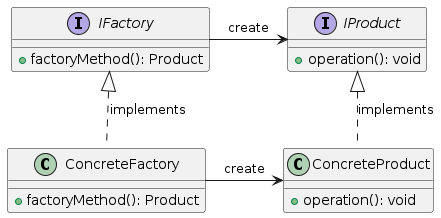
Interfaceではなくて、抽象クラスだが、ざっくりとした対応関係は次の通り:
IFactory → Factory
ConcreteFactory → PipelineFactory
IProduct → Pipelineクラス
ConreteProduct → PipelineLGBなど (pipeline_instances.pyの中のもの)
Framework/factory.py¶
from abc import ABCMeta, abstractmethod
from sklearn.pipeline import Pipeline
class Factory(metaclass=ABCMeta):
@abstractmethod
def create_pipeline(self, str) -> Pipeline:
pass
Pipeline/pipeline_factory.py¶
from Framework.factory import *
from Pipeline.pipeline_instances import *
from enum import Enum
class EPipelineType(Enum):
LGB = 1
RF = 2
LR = 3
CB = 4
class PipelineFactory(Factory):
def create_pipeline(self, pipeline_type : EPipelineType) :
if pipeline_type == EPipelineType.LGB:
return PipelineLGB.get()
if pipeline_type == EPipelineType.RF:
return PipelineRF.get()
if pipeline_type == EPipelineType.LR:
return PipelineLR.get()
if pipeline_type == EPipelineType.CB:
return PipelineCB.get()
else:
return None
Pipeline/pipeline_instances.py¶
class PipelineLGB:
@staticmethod
def get():
drop_columns = []
pipeline = Pipeline([
('activeclient', ActiveClient()),
('ToNa', ReplaceWithNa()),
('binning', Binning()),
('categorical', Categorical()),
#('fillna', FillNa()),
('drop', Drop(drop_columns))
])
return pipeline
class PipelineRF:
@staticmethod
def get():
drop_columns = []
pipeline = Pipeline([
('drop', Drop(drop_columns)),
('onehotencoding', OneHotEncode(one_hot_columns=[])),
('activeclient', ActiveClient()),
('FillNa', FillNa(
{
})),
])
return pipeline
class PipelineLR:
# Logistic regression
@staticmethod
def get():
drop_columns = []
pipeline = Pipeline([
('drop', Drop(drop_columns)),
('FillNa', FillNa()),
("minmax", MinMaxScaler()),
('standard scaler', StandardScaler()),
])
return pipeline
class PipelineCB:
# Catboost
@staticmethod
def get():
drop_columns = []
pipeline = Pipeline([
#('shuffle', Shuffle()),
#('categorical', Categorical()),
('drop', Drop(drop_columns)),
('onehotencoding', OneHotEncode()),
('isnine', ActiveClient()),
('ToNa', ReplaceWithNa()),
('FillNa', FillNa({})),
# ("minmax", MinMaxScaler()),
# ('standard scaler', StandardScaler()),
])
return pipeline
skPlumberBaseについては下記を参考にした。Pipelineに流せるものはBaseEstimator, TransformerMixinを継承している。(https://qiita.com/kazetof/items/fcfabfc3d737a8ff8668)
Model¶
各種モデルの特徴についてはまたあとでまとめる。
ModelについてはOptunaでハイパーパラメータチューニングできるように実装してみた。ここのモデルもinterfaceなりabstract classなりでまとめることができる。
Models/model.py¶
class LGBModel:
def __init__(self) -> None:
print("Created LGB model")
def train(self, x_train, y_train, trials, seed):
objective = Objective_LGB(x_train, y_train, seed)
optuna.logging.set_verbosity(optuna.logging.WARNING)
study = optuna.create_study(direction='maximize', sampler=optuna.samplers.TPESampler(seed=seed)) # 最大化
study.optimize(objective, n_trials=trials, callbacks=[objective.print_best_callback])
classifier = lgb.LGBMClassifier(random_state=seed, **study.best_params)
classifier.fit(x_train, y_train)
return classifier, study.best_value
def predict(self, classifier, test_df):
#classifier = lgb.LGBMClassifier(random_state=seed, **study.best_params)
#classifier.fit(x_train, y_train)
lgb_pred = classifier.predict(test_df)
# 推論
#y_test_pred_proba = model.predict(test_df)
y_test_pred = lgb_pred.round().astype(int) # testの予測値を四捨五入し、0,1にする
return y_test_pred
def save(self, study):
with open('optuna_lgb_model.pkl', mode='wb') as f:
joblib.dump(study, f)
class RandomForestModel:
def __init__(self) -> None:
print("Created Random forest model")
def train(self, x_train, y_train, trials, seed):
params = {
'max_depth': np.arange(2, 10),
'n_estimators': np.linspace(10, 100, 1, dtype='int')
}
grid_rf_model = GridSearchCV(
RandomForestClassifier(random_state=seed),
param_grid=params,
cv=5,
scoring='f1',
n_jobs=-1,
)
grid_rf_model.fit(x_train, y_train)
return grid_rf_model.best_estimator_, grid_rf_model.best_score_
def predict(self, classifier, test_df):
rf_pred = classifier.predict(test_df)
y_test_pred = rf_pred.round().astype(int) # testの予測値を四捨五入し、0,1にする
return y_test_pred
class LogisticRegressionModel:
#ref https://scikit-learn.org/stable/auto_examples/compose/plot_digits_pipe.html
def __init__(self) -> None:
print("Created logistic regression model")
def train(self, x_train, y_train, trials, seed):
params= {
"pca__n_components": np.arange(2,len(x_train.columns)),
"logistic__C": np.logspace(-4, 4, 2),
}
logistic = LogisticRegression(max_iter=10000, tol=0.1)
standard_scaler = StandardScaler()
pca = PCA()
model_pipeline = Pipeline([
#("minmax", MinMaxScaler()),
('standard scaler', standard_scaler),
("pca", pca),
("logistic", logistic)
])
grid_lr_model = GridSearchCV(
model_pipeline,
param_grid=params,
cv=5,
scoring='f1',
n_jobs=-1,
)
grid_lr_model.fit(x_train, y_train)
print("best params:", grid_lr_model.best_params_)
return grid_lr_model.best_estimator_, grid_lr_model.best_score_
def predict(self, classifier, test_df):
#test_df = self.pipe.transform()
print("using params..." , classifier.get_params())
lr_pred = classifier.predict(test_df)
y_test_pred = lr_pred.round().astype(int) # testの予測値を四捨五入し、0,1にする
return y_test_pred
class CatBoostModel:
def __init__(self) -> None:
print("Created CatBoost model")
def train(self, x_train, y_train, trials, seed):
objective = Objective_CatBoost(x_train, y_train, seed)
optuna.logging.set_verbosity(optuna.logging.WARNING)
study = optuna.create_study(direction='maximize', sampler=optuna.samplers.TPESampler(seed=seed)) # 最大化
study.optimize(objective, n_trials=trials, callbacks=[objective.print_best_callback])
classifier = CatBoostClassifier(random_state=seed, **study.best_params)
classifier.fit(x_train, y_train)
return classifier, study.best_value
def predict(self, classifier, test_df):
cb_pred = classifier.predict(test_df)
# 推論
y_test_pred = cb_pred.round().astype(int) # testの予測値を四捨五入し、0,1にする
return y_test_pred
def save(self, study):
with open('optuna_catboost_model.pkl', mode='wb') as f:
joblib.dump(study, f)
実行¶
実行のイメージ (main)
main.py¶
def main():
DIR_PATH = ""
OUTPUT_PATH="Output"
train_df = pd.read_csv(DIR_PATH + 'data/train.csv') # train.csvの読み込み
test_df = pd.read_csv(DIR_PATH + 'data/test.csv') # test.csvの読み込み
train_df = shuffle(train_df, random_state=0)
model = LGBModel()
factory: Factory = PipelineFactory()
pipeline = factory.create_pipeline(EPipelineType.LGB)
train_pipe = Pipeline([
('common', pipeline),
('xy', SplitXY())
])
# 学習モデルの構築 (前処理だけ)
X_train, y_train = train_pipe.transform(train_df)
# モデルで学習
best_model, best_score = model.train(X_train, y_train, trials=100, seed=1234)
#スコアを見てみる
print("best_score: ", best_score)
#結果を出力する
Util.write_submit_file(OUTPUT_PATH, y_test_pred)
Util.output_pipeline_diagram(OUTPUT_PATH, pipeline)
if __name__ == '__main__':
main()